ripgrep:高性能命令行文本搜索工具
BurntSushi开源的命令行搜索工具ripgrep,目前累计获得63714个Star,项目地址:https://github.com/BurntSushi/ripgrep
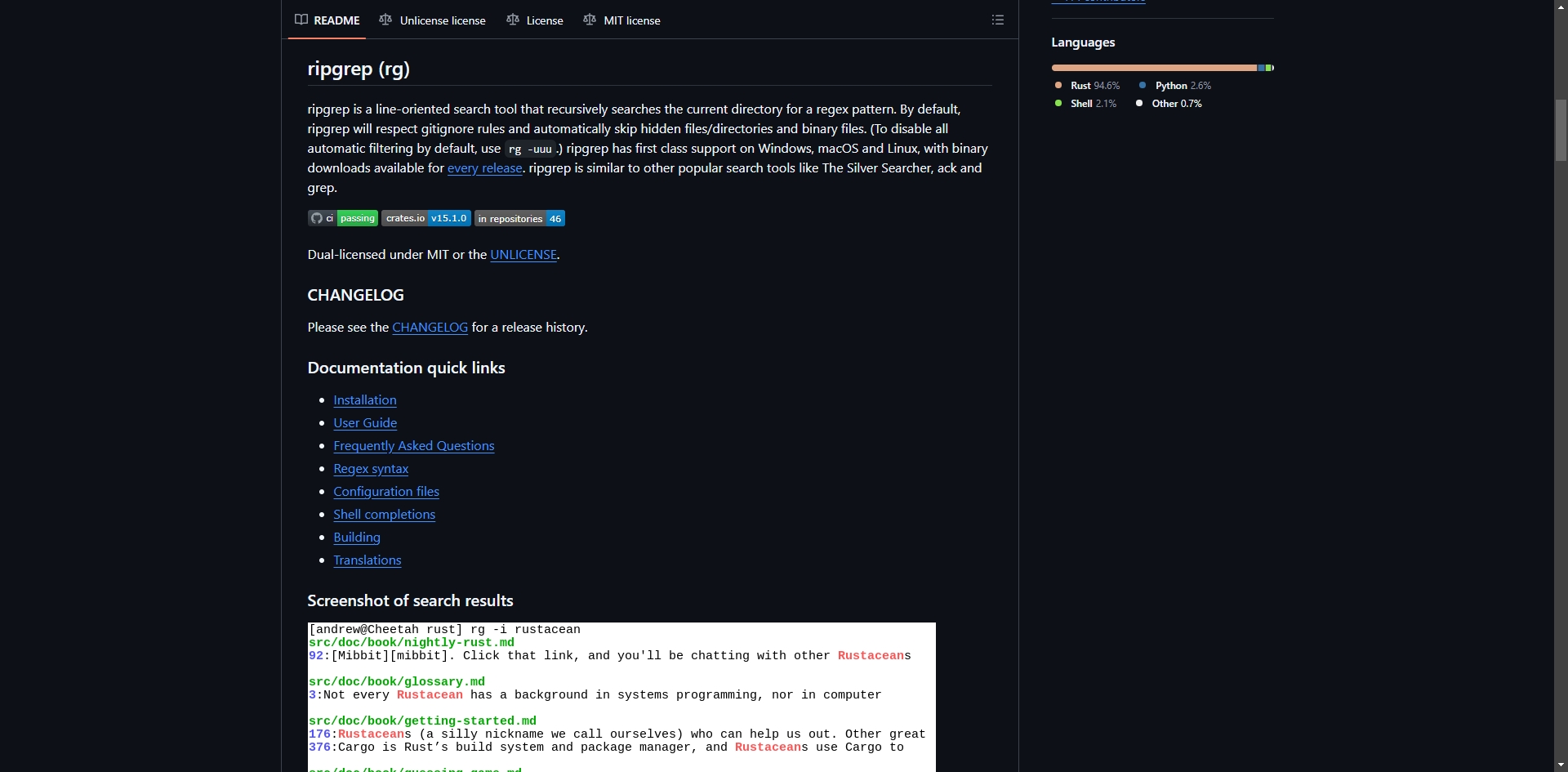
ripgrep是一款面向行的递归搜索工具,可在当前目录中匹配正则表达式模式。默认情况下,ripgrep会遵守gitignore规则,自动跳过隐藏文件、目录和二进制文件。用户可通过rg -uuu命令关闭所有自动过滤规则。ripgrep支持Windows、macOS和Linux系统,每个版本都提供预编译的二进制文件可供下载。其功能与Silver Searcher、ack、grep等常用搜索工具类似。
公开测试数据显示,ripgrep的搜索速度显著快于同类工具。在Linux内核源码树中搜索指定正则模式,ripgrep耗时0.082秒,是同条件下git grep的3.34倍,是The Silver Searcher的5.43倍。在单个13GB大小的文本文件中搜索指定模式,ripgrep耗时1.042秒,是同条件下GNU grep的6.31倍。即使在没有字面量优化机会的复杂模式搜索场景中,ripgrep的性能也领先于同类工具。
ripgrep默认启用递归搜索和自动过滤功能,不会搜索被.gitignore、.ignore、.rgignore等规则忽略的文件,也不会搜索隐藏文件和二进制文件。自动过滤功能可通过rg -uuu命令完全关闭。
ripgrep支持按文件类型搜索,用户可通过-t参数指定搜索特定类型的文件,例如rg -tpy foo将仅搜索Python文件,或通过-T参数排除指定类型的文件,例如rg -Tjs foo将排除JavaScript文件。用户可自定义新的文件类型匹配规则。
ripgrep支持grep工具的常用功能,包括显示搜索结果上下文、多模式搜索、匹配结果高亮和全Unicode支持。与GNU grep不同,ripgrep在开启Unicode支持的同时保持较高的运行速度,Unicode支持默认处于启用状态。
ripgrep可选切换为PCRE2正则引擎,支持环视和反向引用等默认引擎不具备的功能。PCRE2支持可通过-P/–pcre2参数永久启用,或通过–auto-hybrid-regex参数仅在需要时启用。
ripgrep支持替换功能,可根据匹配结果重写输出内容。支持搜索UTF-8之外的文本编码,包括UTF-16、latin-1、GBK、EUC-JP、Shift_JIS等,用户可通过-E参数指定文件编码,工具也支持自动检测UTF-16编码。
ripgrep支持搜索brotli、bzip2、gzip、lz4、lzma、xz、zstandard等常见格式的压缩文件,用户可通过-z参数启用该功能。支持自定义输入预处理过滤器,可实现PDF文本提取、文件解密、自动编码检测等扩展功能。
ripgrep支持通过配置文件设置默认参数,无需每次输入重复的命令行参数。
ripgrep的二进制文件名为rg,用户可通过多种方式安装。macOS或Linux用户可通过brew install ripgrep安装。Windows用户可通过choco install ripgrep、scoop install ripgrep或winget install BurntSushi.ripgrep.MSVC安装。各Linux发行版大多已将ripgrep纳入官方软件源,用户可直接通过对应包管理器安装。Rust开发者可通过cargo install ripgrep从源码编译安装,最低支持Rust 1.85.0版本。
基本使用方式为rg [参数] 搜索模式,例如rg -n -w 'test'将在当前目录递归搜索完整单词test,并显示匹配行的行号。
开源地址:https://github.com/BurntSushi/ripgrep